| 小型无人艇研究现状及关键技术 |
| |
| 引用本文: | 宋利飞, 许传毅, 郝乐, 等. 基于改进DDPG算法的无人艇自适应控制[J]. 中国舰船研究, 2024, 19(1): 137–144. doi: 10.19693/j.issn.1673-3185.03122 |
| |
| 作者姓名: | 宋利飞 许传毅 郝乐 郭荣 柴威 |
| |
| 作者单位: | 1.武汉理工大学 高性能船舶技术教育部重点实验室,湖北 武汉 430063;2.武汉理工大学 船海与能源动力工程学院,湖北 武汉 430063 |
| |
| 基金项目: | 国家自然科学基金资助项目(52201379);中央高校基本科研业务费专项资金资助项目(3120622898) |
| |
| 摘 要: | 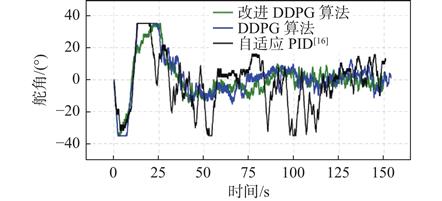
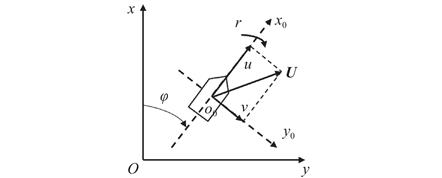
目的针对水面无人艇(USV)在干扰条件下航行稳定性差的问题,提出一种基于深度强化学习(DRL)算法的智能参数整定方法,以实现对USV在干扰情况下的有效控制。 方法首先,建立USV动力学模型,结合视线(LOS)法和PID控制器对USV进行航向控制;其次,引入DRL理论,设计智能体环境状态、动作和奖励函数在线调整PID参数;然后,针对深度确定性策略梯度 (DDPG)算法收敛速度慢和训练时容易出现局部最优的情况,提出改进DDPG算法,将原经验池分离为成功经验池和失败经验池;最后,设计自适应批次采样函数,优化经验池回放结构。 结果仿真实验表明,所改进的算法迅速收敛。同时,在训练后期条件下,基于改进DDPG算法控制器的横向误差和航向角偏差均显著减小,可更快地贴合期望路径后保持更稳定的路径跟踪。 结论改进后的DDPG算法显著降低了训练时间成本,不仅增强了智能体训练后期的稳态性能,还提高了路径跟踪精度。
|
| 关 键 词: | 无人艇 深度强化学习 智能控制 轨迹跟踪 参数整定 |
| 收稿时间: | 2022-10-11 |
| 修稿时间: | 2022-11-11 |
Research status and key technologies of small USV |
| |
| SONG L F, XU C Y, HAO L, et al. Adaptive control of unmanned surface vehicle based on improved DDPG algorithm[J]. Chinese Journal of Ship Research, 2024, 19(1): 137–144 (in Chinese). doi: 10.19693/j.issn.1673-3185.03122 |
| |
| Authors: | SONG Lifei XU Chuanyi HAO Le GUO Rong CHAI Wei |
| |
| Affiliation: | 1.Key Laboratory of High Performance Ship Technology of Ministry of Education, Wuhan University of Technology, Wuhan 430063, China;2.School of Naval Architecture, Ocean and Energy Power Engineering, Wuhan University of Technology, Wuhan 430063, China |
| |
| Abstract: |
ObjectiveIn order to tackle the issue of the poor navigation stability of unmanned surface vehicles (USVs) under interference conditions, an intelligent control parameter adjustment strategy based on the deep reinforcement learning (DRL) method is proposed. MethodA dynamic model of a USV combining the line-of-sight (LOS) method and PID navigation controller is established to conduct its navigation control tasks. In view of the time-varying characteristics of PID parameters for course control under interference conditions, the DRL theory is introduced. The environmental state, action and reward functions of the intelligent agent are designed to adjust the PID parameters online. An improved deep deterministic policy gradient (DDPG) algorithm is proposed to increase the convergence speed and address the issue of the occurrence of local optima during the training process. Specifically, the original experience pool is separated into success and failure experience pools, and an adaptive sampling mechanism is designed to optimize the experience pool playback structure. ResultsThe simulation results show that the improved algorithm converges rapidly with a slightly improved average return in the later stages of training. Under interference conditions, the lateral errors and heading angle deviations of the controller based on the improved DDPG algorithm are reduced significantly. Path tracking can be maintained more steadily after fitting the desired path faster.ConclusionThe improved algorithm greatly reduces the cost of training time, enhances the steady-state performance of the agent in the later stages of training and achieves more accurate path tracking.
|
| |
| Keywords: | USV deep reinforcement learning intelligent control trajectory tracking parameter setting |
|
| 点击此处可从《中国舰船研究》浏览原始摘要信息 |
|
点击此处可从《中国舰船研究》下载全文 |